 Chapyter is a JupyterLab extension that seamlessly connects GPT-4 to your coding environment. It features a code interpreter that can translate your natural language description into Python code and automatically execute it. Incorporating powerful code generation models like GPT-4 into the notebook coding environment opens up new modes of human-AI collaboration. By enabling “natural language programming” in your most familiar IDE, Chapyter can boost your productivity and empower you to explore many new ideas that you would not have tried otherwise.
Chapyter is a JupyterLab extension that seamlessly connects GPT-4 to your coding environment. It features a code interpreter that can translate your natural language description into Python code and automatically execute it. Incorporating powerful code generation models like GPT-4 into the notebook coding environment opens up new modes of human-AI collaboration. By enabling “natural language programming” in your most familiar IDE, Chapyter can boost your productivity and empower you to explore many new ideas that you would not have tried otherwise.
Why building Chapyter?
Here is a tldr version of the motivation:
- Sometimes, I want to have an AI agent to take on some coding tasks, i.e., generating and executing the code and showing me the results based on some natural language instruction.
- I want the AI agent to be fully integrated in my IDE such that it can provide context-aware support and I can easily inspect and edit the generated code.
- I want transparency on how the code is generated (knowing the prompts) and want to customize the code generation sometimes
- I want to keep my code and data private as much and I am hesitant to upload any WIP progress code/data elsewhere.
I love and hate autocomplete – since the initial launch of TabNine in 2017, autocompletion has been the mainstream interaction for many AI-assisted coding tools. Autocomplete assistants act as if you are pairing programming with an agent who only produces short code snippets in addition to your code. It offers one of the most straightforward interactions that bring AI support in the context of coding and can significantly boost productivity and satisfaction in developers’ work.1 Yet autocomplete is not perfect: interspersing AI code suggestions can be distracting, the generated code might contain hidden bugs that could be very hard to debug, and the generated code often spans only a few lines and it’s hard to produce new functions outside of the context.
What if the “collaborator” takes on some coding tasks sometimes? We very frequently write similar or even duplicated code for tasks like loading data from json, transforming the pandas dataframe and visualization, modifying huggingface trainers, etc. Imagine if we just need to describe the task in natural language and the assistant can do the rest—generating and executing the code—and we can see the results and just focus on the next task. While it sounds like autocompletion at first, this setup represents a very different mode of collaboration other than pair programming: the assistant acts as if another programmer commits code to the same project and you can see the results immediately. And I very much want to have one such assistant in my IDE.
One other reason is that the current AI coding assistant is often opaque about their setups, and you are sharing your interaction data and coding history when using the service. In terms of privacy, for example, according to Copilot’s privacy statement,2 the user engagement data, “including pseudonymous identifiers and general usage data”, is collected, processed, and shared with Microsoft while you use GitHub Copilot: It doesn’t mention an option to opt out of this data collection. The recent ChatGPT code interpreter plugin is only activated when you opt-in the “Chat history & training” function,3 and whatever documents and code you uploaded could be seen and used by OpenAI for future training. Moreover, it is never clear what prompts are used by Copilot, let alone the option to create your own customized prompts for coding.
Key features of Chapyter
Chapyter is designed to support generating and executing code for complete tasks.
When people code in notebooks, they often write code in a “fragmented” way: they write a few lines of code, execute it, and then write more in the next cell. The task or the goal in each cell is often small and somewhat independent from the other cells. Sometimes the next task could be very different from the previous one. For example, in the middle of implementing a neural network, you might need to add the dataset loader and that requires completely different types of thinking and coding. The task-switching is often distracting and could easily cause fatigue and reduce productivity. Sometimes you might just want to type “Please load the dataset in a way to test the neural network” and let the computer do the rest.
Chapyter helps overcome this issue by providing cell-level code generation and automatic execution. For a new cell, you can simply type a natural language description of what you want to do, and Chapyter will invoke GPT-X model to generate the code and execute it for you. This is very different from code completion in systems like Copilot: code completion is designed to support micro-tasks that span only a few lines of code and are very relevant to current work, e.g., completing a function call, while Chapyter aims to take over complete tasks and that could be sometimes different from the existing code.
The example below starts with implementing the code to calculate the first 50 terms in the Fibonacci sequence.
Simply adding the magic command %%chat at the beginning of the cell of a natural language description of the code, the results are shown in a few seconds after execution, no Google search or copy-paste between ChatGPT and the notebook is needed.
By default the generated code is hidden, as we want to deemphasize the AI-generated code and focus on the results (though don’t worry, we have a safe mode to prevent the auto execution of possibly dangerous code).
It is very pleasant to see the code correctly generated when I first run this demo. While it is not surprising that GPT-4 can do this, having an end-to-end pipeline where the prompt and the code all lives in your IDE is something different, let alone the code can be automatically executed.

Chapyter offers a transparent way for using powerful AI to assist programming.
Chapyter is a minimal Python package that can be installed locally and used seamlessly with JupyterLab. It calls the GPT-X models using the OpenAI API, by which the interaction data and code will not be kept for training by default.4 All the pre-defined prompts and “programs” are available in the library,5 and it allows you to load your customized prompts as well.
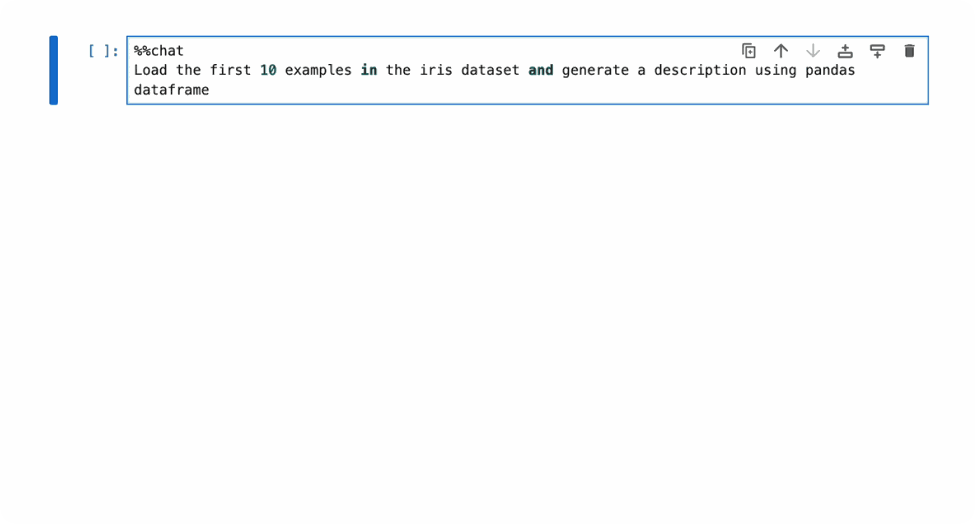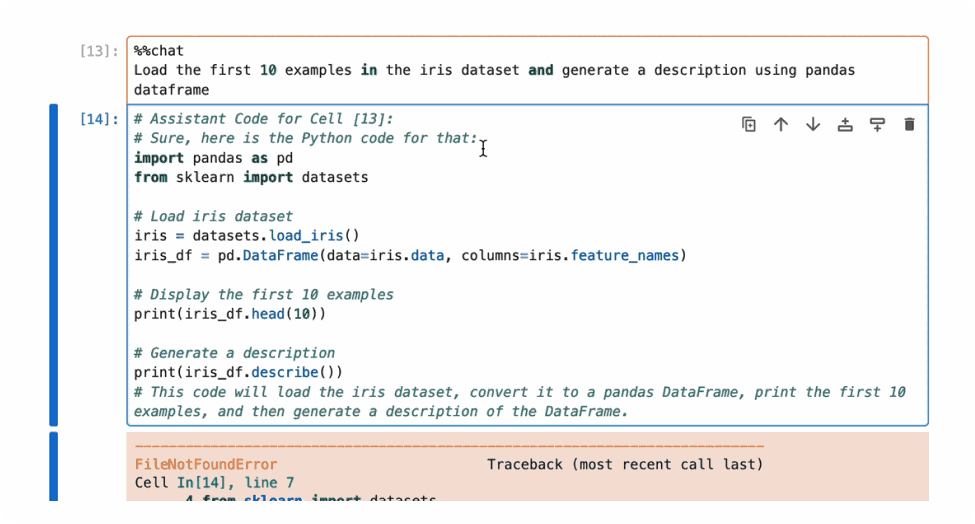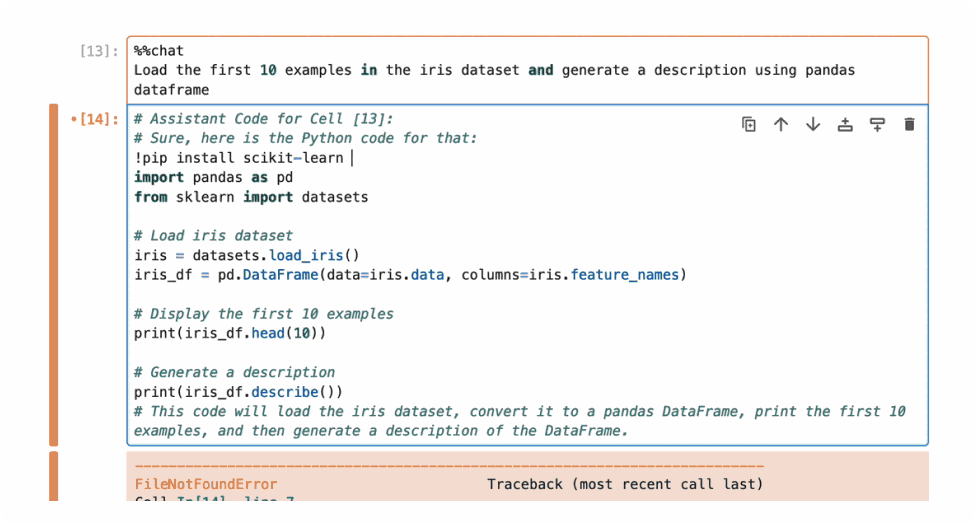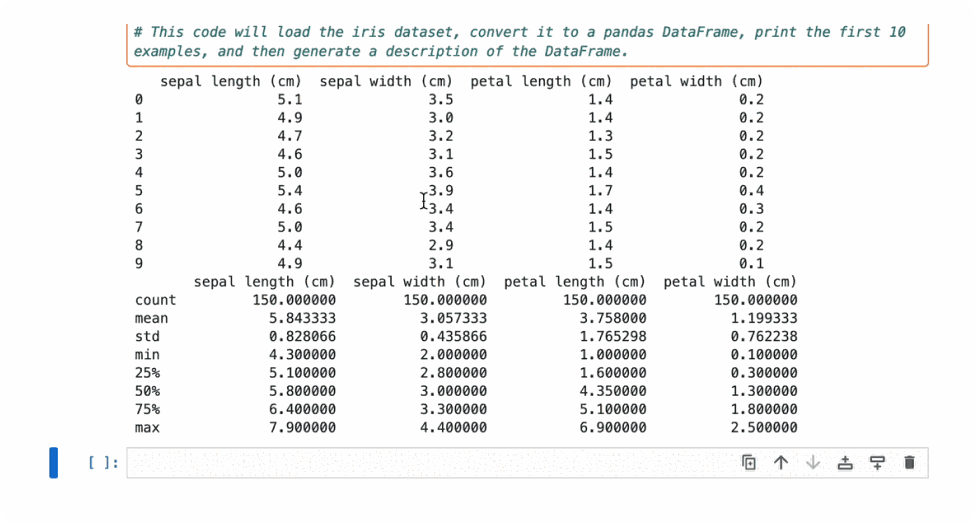
Chapyter can leverage your code history and execution outputs to provide context-aware suggestions. It can also opt to load files in order to provide suggestions for further processing and analysis. For example, in the example below, Chapyter is generating visualizations for the loaded iris dataset. However, since it’s integrated with your local coding environment, the files will not be uploaded elsewhere, and you can choose to what extent to expose the data to the assistant.6
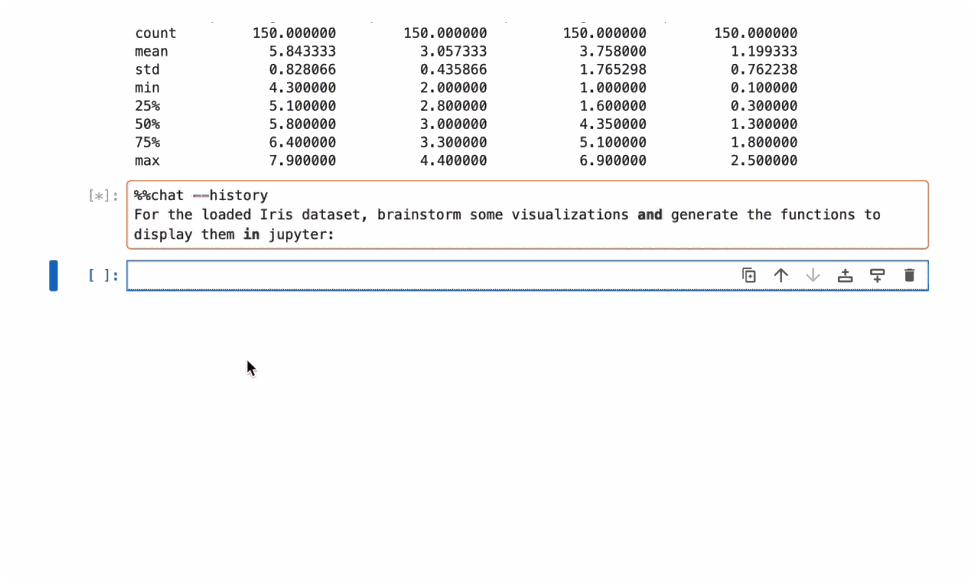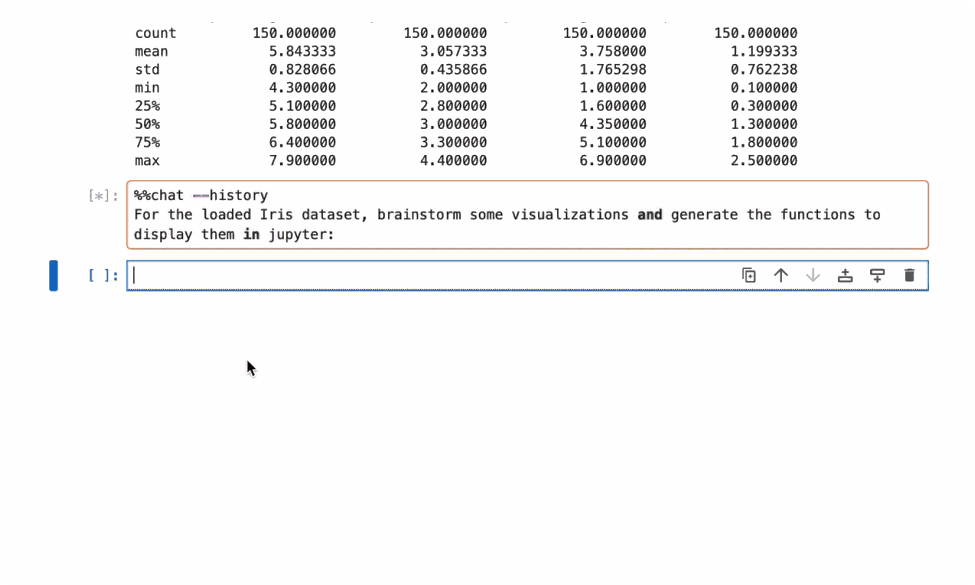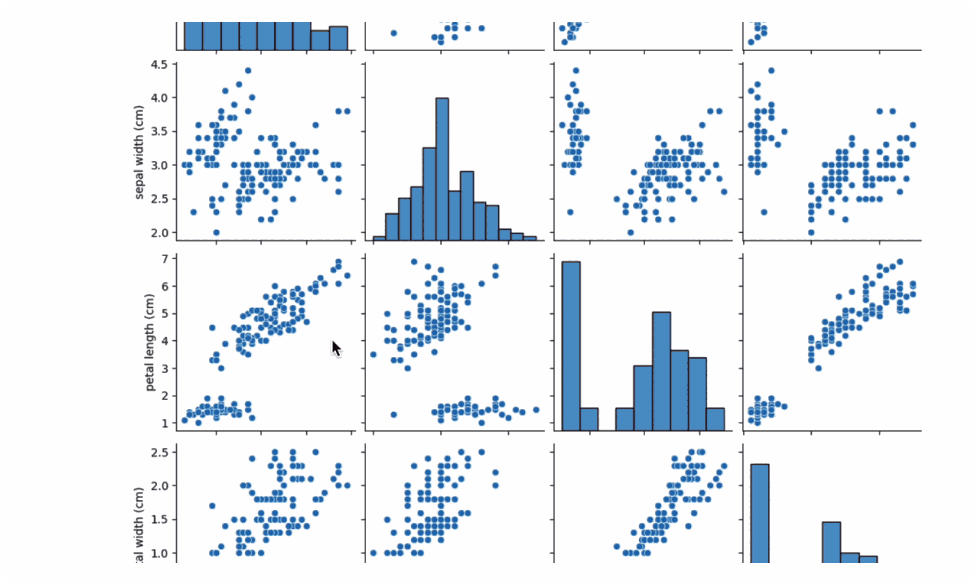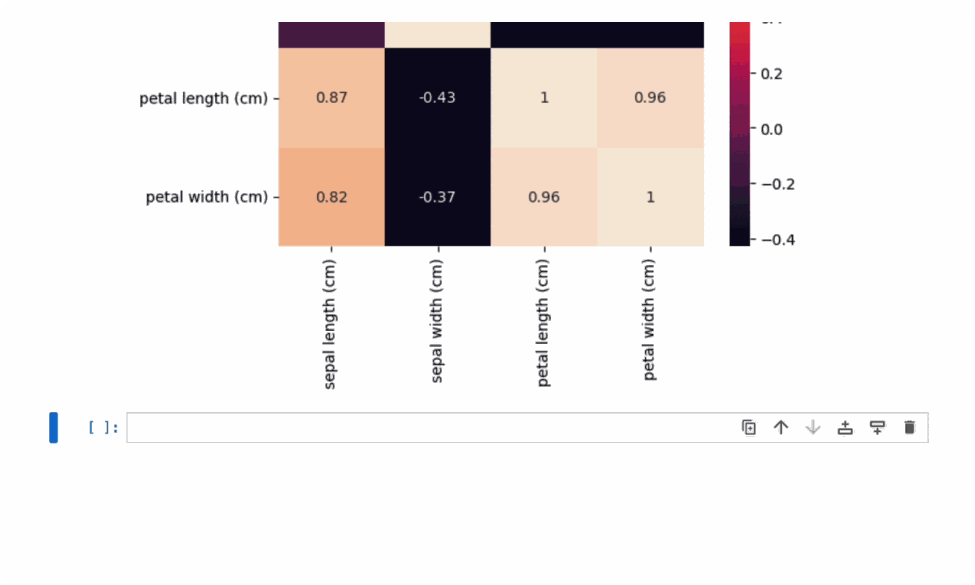
Chapyter also enables seamless transitions between human and AI coding.
Keeping in mind that the current AIs are still not perfect, the design of Chapyter enables easy debugging and correction of the generated code.
For example, in the example below, the generated code misses the installation of the scikit-learn package and raises an error, and the user can inspect and add the fix in context, reducing context switching.
Chapyter vs other assistants
To summarize, Chapyter is distinguished from other coding assistants in the following dimensions:
| Functionality | Chapyter | Copilot | CopilotX | ChatGPT | ChatGPT Code Interpreter |
|---|---|---|---|---|---|
| IDE integration & In-situ debugging | Yes | Yes | Yes | No | No |
| Assisting coding tasks of varied complexity | Yes | No | Yes | Yes | Yes |
| Automatic execution of AI generated code | Yes | No | No | No | Yes |
| Using execution history / outputs for code suggestion | Yes | No | No | No | Yes |
| Transparent about the used prompts or configuration? | Yes | No | No | Maybe | Maybe |
| Customizing prompts / agents for coding | Yes | No | No | No | No |
| Keeping your data and interaction private | Yes | No | No | No | No |
How did I make Chapyter?
There are two major components in Chapyter: implementing the ipython magic command that handles the prompting and calling GPT-X models, and the frontend that listens to Chapyter cell execution and automatically executes the newly generated cell and updates the cell styles. The chart below illustrates the orchestration of the frontend and ipython kernel after a Chapyter cell is executed.
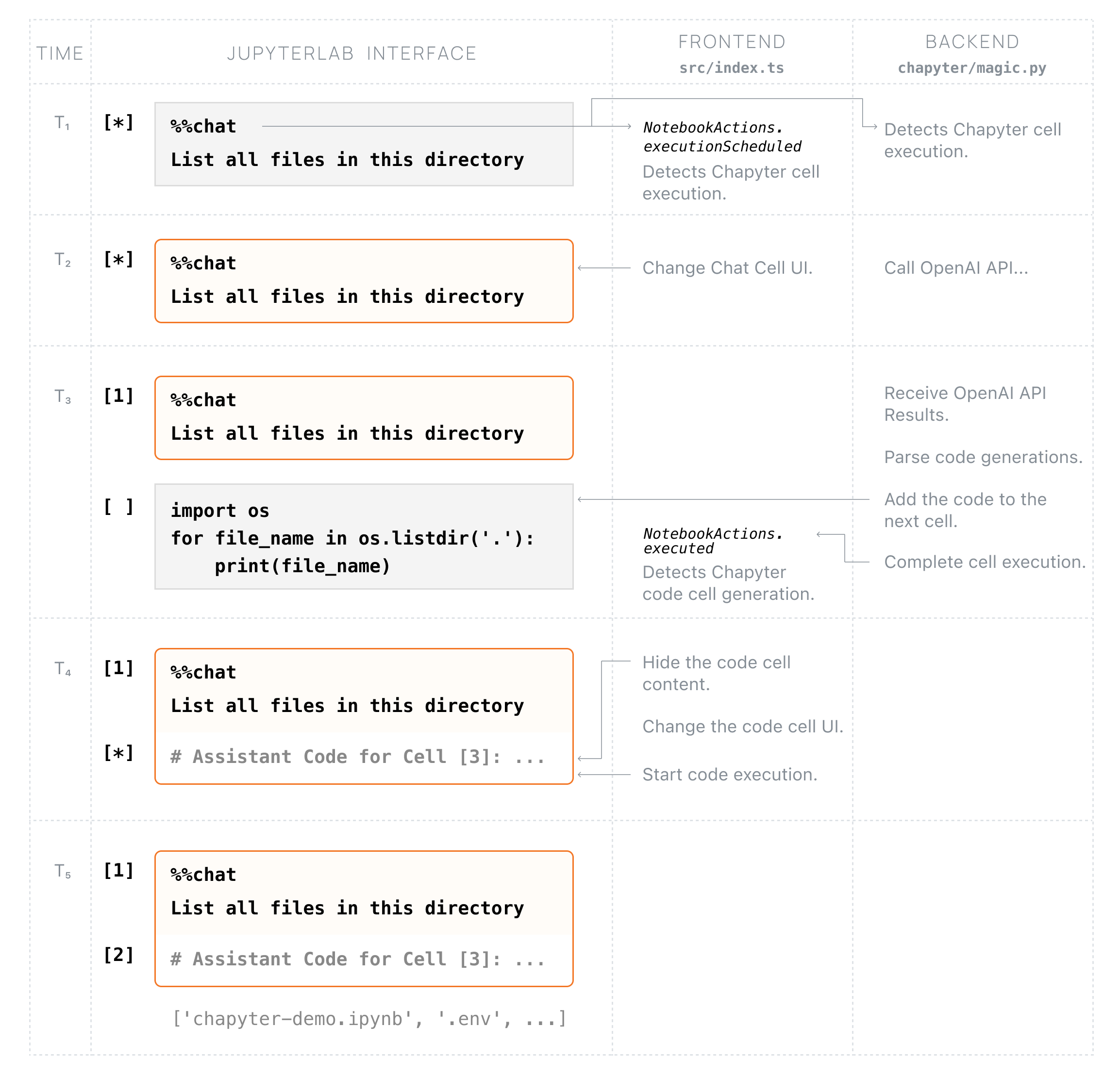
Next steps
Chapyter is currently on public alpha and we plan to add many important and exciting updates that enables better customization and enhancing safety of the code generation and execution shortly. We are very curious and excited to test it out in complicated and challenging real-world coding tasks, e.g., providing the right support inside a jupyter notebook of 300 cell executions. Please try out our tools and stay tuned for more updates, and we look forward to your feedback.
Reference
-
See GitHub’s blogpost on Research: quantifying GitHub Copilot’s impact on developer productivity and happiness. ↩
-
Last accessed in July 2023: wayback machine link. ↩
-
This is a feature only for ChatGPT Plus users, and in order to use any plugin functions, one needs to turn on the “Chat history & training” function. ↩
-
See in chapyter/programs.py. ↩
-
By turning off the “history” flag, Chapyter will not send your coding history to OpenAI API. ↩