








Launching the Augmented Mind Podcast
Awards at NeurIPS 2025 Workshops
Our recent papers are recognized at several NeurIPS 2025 workshops
Talk at the Scale ML Seminar Series @ MIT
LaText: Interleave Latent and Text Chain-of-Thought for efficient reasoning
Workshop Organizing
Co-organizing the LM4Sci Workshop at COLM 2025
Talk at Stanford HCI Group Lunch Seminar
Rethinking the Design and Evaluation of Human and LLM Collaboration
News
Co-LLM and SymGen are covered by MIT News
Organizing a New Seminar Series at MIT
MIT NLP Meetings Seminar Series
Talk at University of Washington
Co-LLM: Training LLMs to Decode Collaboratively
News
Student Spotlight interview by CSAIL Alliances
Talk at Google Research
Developing User-Friendly Language Language Model Systems
RSAP panel at the American Literature Association conference
LayoutParser and Historical Document Image Processing
Talk at Ranjay Krishna’s Group @ UW
Developing User-Friendly Language Language Model Systems
Talk at MIT Sloan AI/ML Conference
Towards Verifiable Text Generation for Developing Trustworthy LLMs
Discussion on Image Extraction, hosted by Thomas Smits at University of Amsterdam
LayoutParser and Historical Document Image Processing
Instructor for an MIT IAP Class
Visual Design in Scholarly Communication
Blog Post
Introducing Chapyter
Talk at Nigam Shah’s Group Meeting @ Stanford
Redesigning Clinical Documentation
Talk at Natural Legal Language Processing workshop @ EMNLP 2022
Multi-LexSum: Real-world Summaries of Civil Rights Lawsuits at Multiple Granularities
Guest Lecture in CSE 599D @ UW, hosted by Prof. Jeff Heer
Visual Content Extraction for Scientific Documents

Together with Yijia Shao and Michael Ryan, we started a new podcast series called Augmented Mind Podcast, focusing on technical human-centered AI work.

Our recent papers are recognized at NeurIPS 2025:
- The Collaborative Effort Scaling framework is recognized as the best paper at the NeurIPS 2025 Workshop on Socially Responsible and Trustworthy Foundation Models (ResponsibleFM).
- The Hybrid CoT (LaText) paper is recognized as a spotlight paper at the NeurIPS 2025 Workshop on Efficient Reasoning.

I gave a talk on our recent work on LaText, a novel approach to interleave latent and text chain-of-thought for efficient reasoning.
I’m co-organizing the Workshop on Large Language Modeling for Scientific Discovery (LM4Sci) at COLM 2025 in Montreal.

I shared an initial version of our collaborative effort scaling paper, and discussed the HCI aspects of our previous work on Symbolic Generation.

Check the MIT News articles covering our recent projects:

Pratyusha Sharma and I started to organize a new NLP seminar series at MIT. It features NLP researchers working on a diverse set of topics ranging from LLMs, interpretability, Human AI Collaboration, and more.

This talk is hosted by Luke Zettlemoyer’s group. We go through the details of our ACL paper Co-LLM. You can find the slides here.
In a recent interview by CSAIL Alliances, I shared our recent work on Co-LLM and SymGen and described my vision for building better language model or AIs with a human-centered perspective.
This talk is hosted by Chiyuan Zhang and Yangsibo Hunag. We focused on the Co-LLM project and had a deep dive in the methodology and experiments. Slides available upon request.
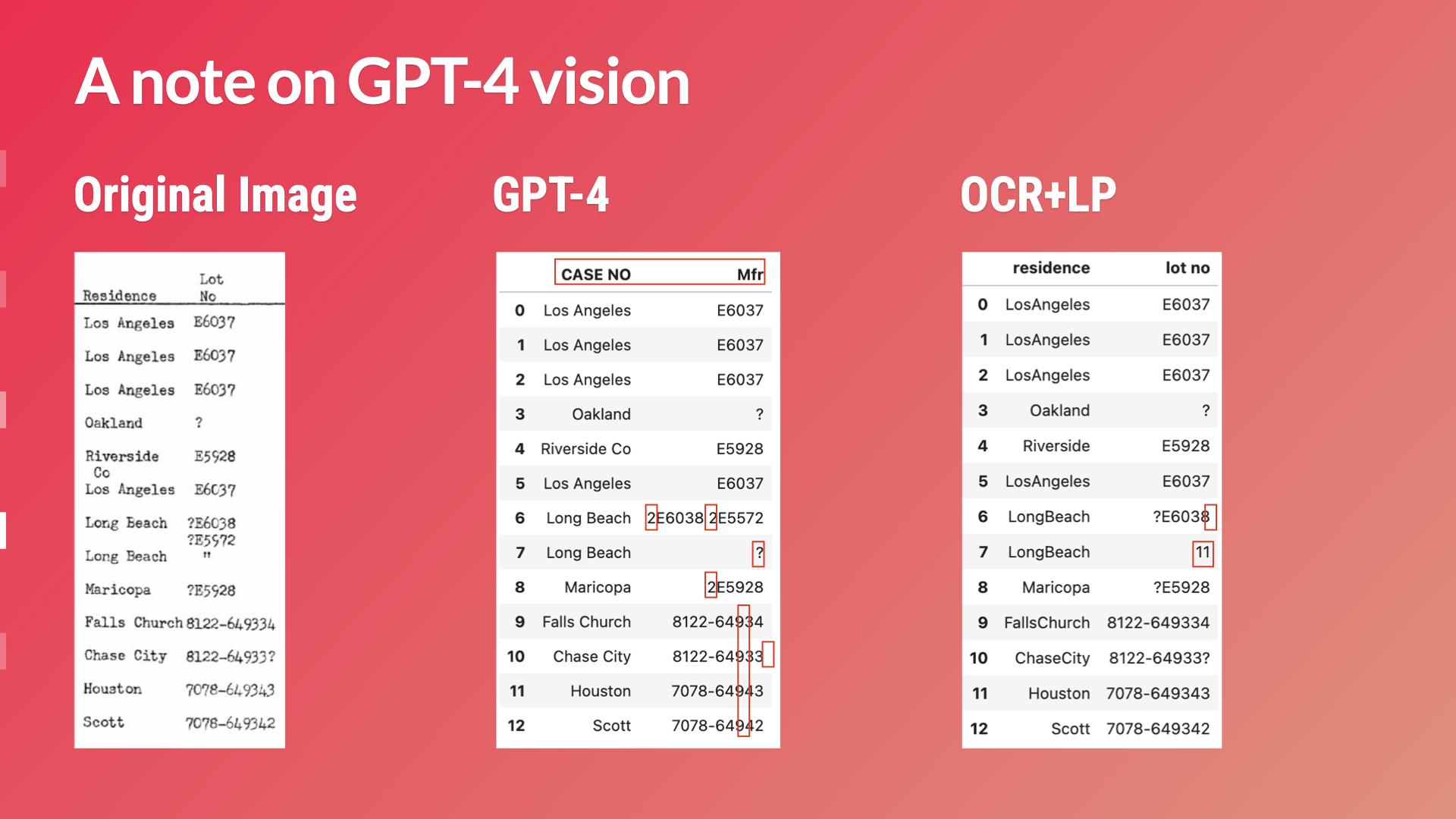
We reviewed the LayoutParser design and functionality, as well as approaches to tackle historical image processing and extraction in 2024. Slides available upon request.
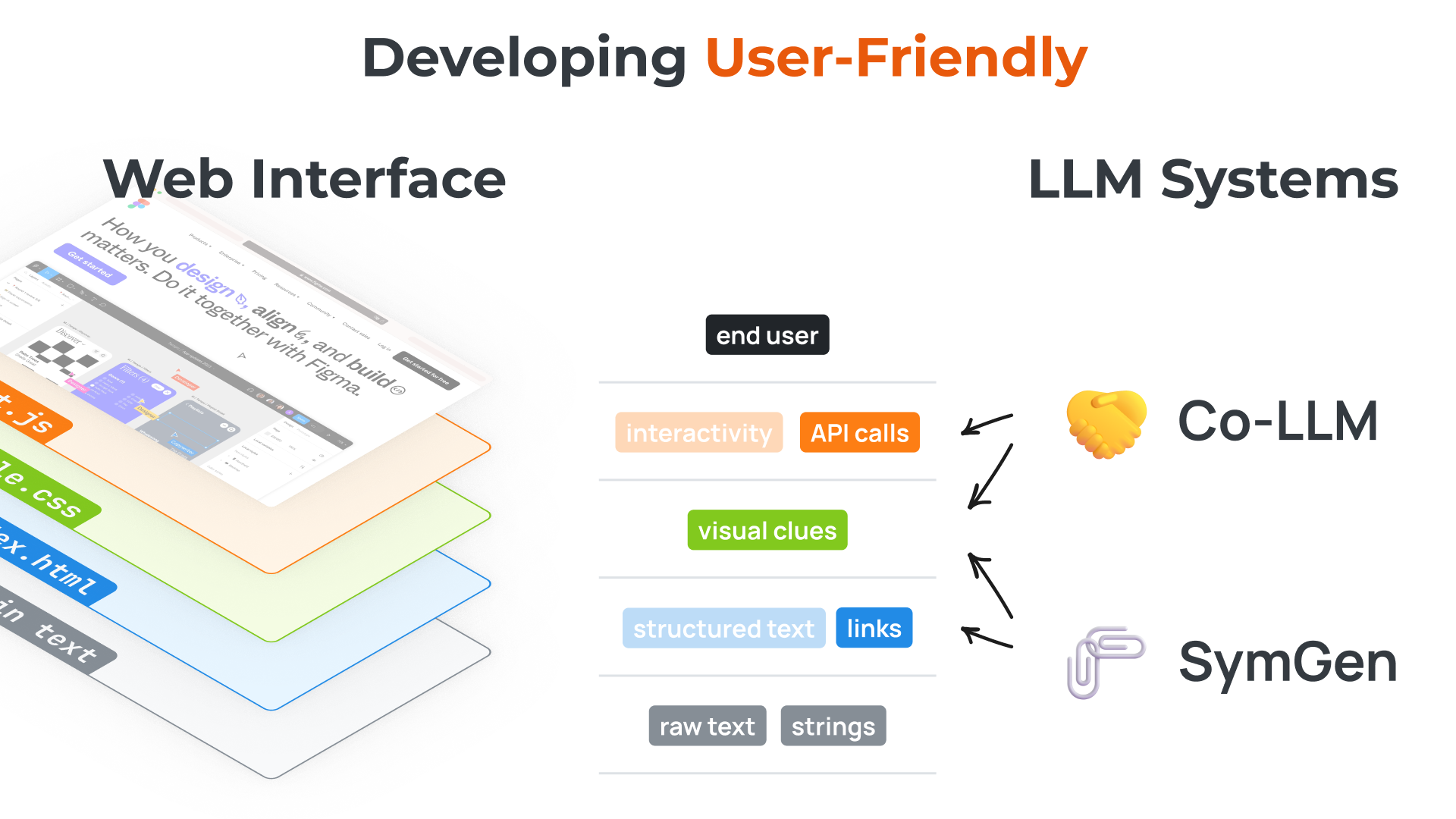
We start with the analogy between web interface development and llm development: LLM can produces raw text (as if htmls for the web pages) – what is the CSS and javascript in the context of LLMs? We then talk about two recent projects, Co-LLM and SymGen, drawing connections between our methods and web technologies like CSS, API calls, etc. Slides available upon request.
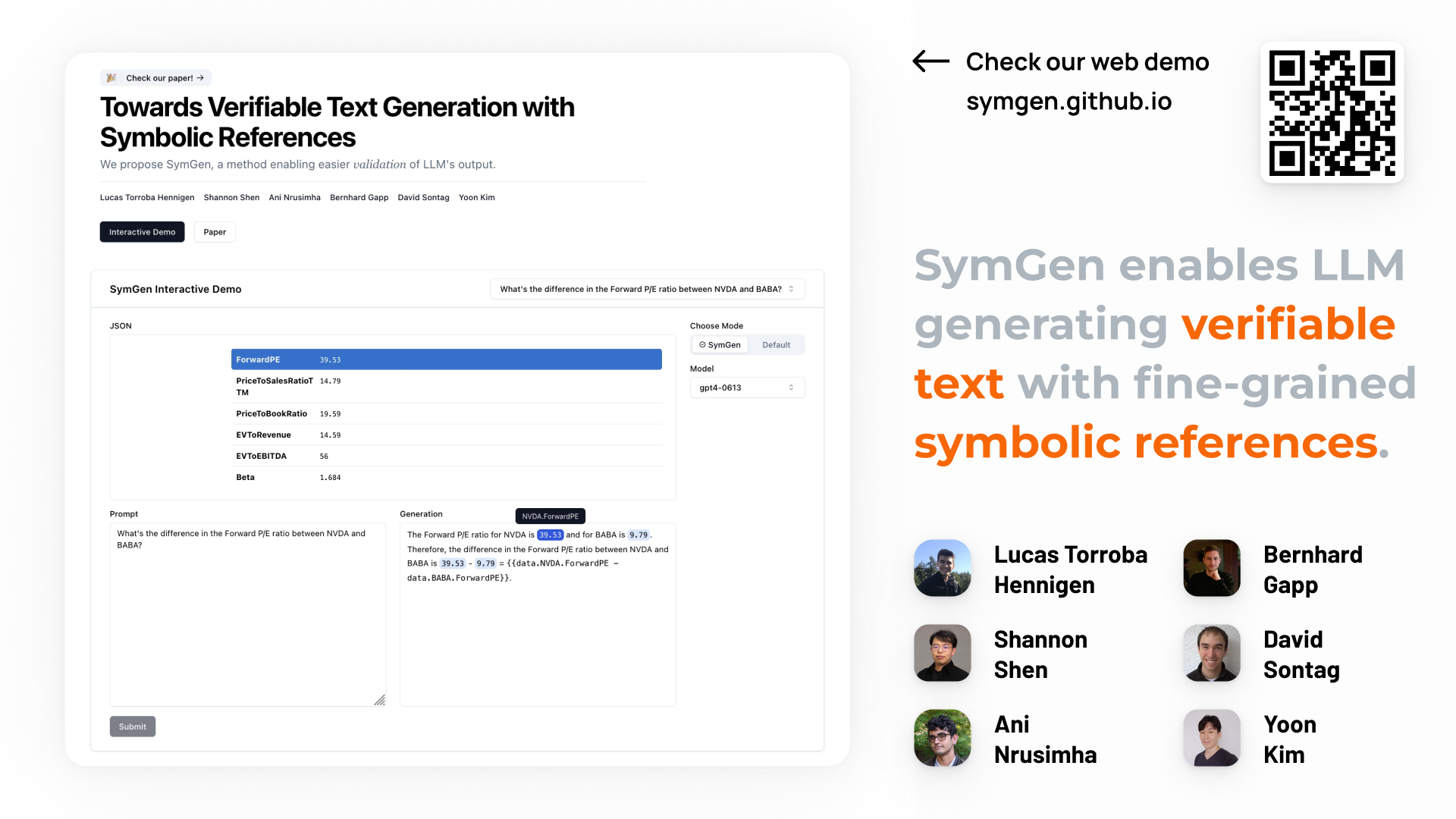
In this short talk, we cover our latest research on SymGen, a novel approach to generating verifiable text for developing trustworthy LLMs. Slides available upon request.
We reviewed the LayoutParser design and functionality, as well as approaches to tackle historical image processing and extraction in 2024. Slides available upon request.
A series of lectures over the MIT IAP period, co-taught with Lucas Torroba Hennigen, focused on visual design in scholarly communication. Visual design is a crucial element in various forms of scientific communication, ranging from papers, slides, to even videos. While there is an increasing need for researchers to produce high-quality visuals, it remains to be a time-consuming and sometimes very challenging task. Despite the significant role they play, there is a noticeable lack of formal education dedicated to this aspect. This subject aims to cover several key topics about visual designs in scholarly communication.
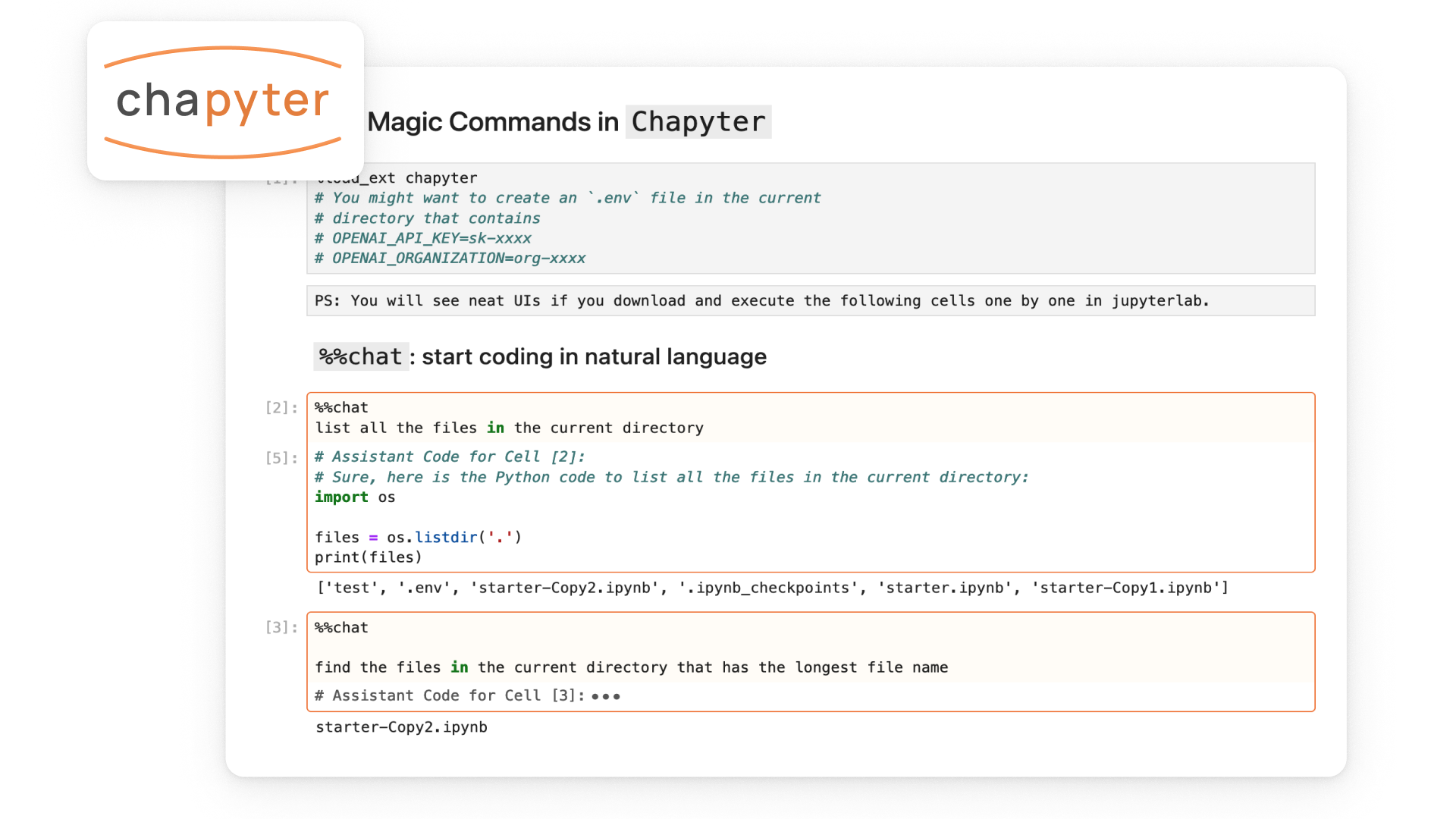
Chapyter is a JupyterLab extension that seamlessly connects GPT-4 to your coding environment. It features a code interpreter that can translate your natural language description into Python code and automatically execute it.

We took the inspiration from our position paper on AI supported expository writing and discuss how to apply such ideas in clinical documentation. This is a joint presentation with Monica Agrawal and Hunter Lang.
A presentation of our work on the Multi-LexSum dataset, containing real-world summaries of civil rights lawsuits at multiple granularities.
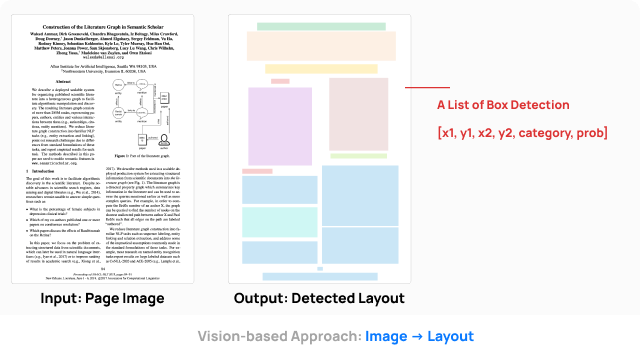
We reviewed the general problem of visual content extraction in scientific documents, as well as the current state-of-the-art methods and challenges. Slides available upon request.


















{kind=link}
{kind=link}