Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems where human goals are often underspecified and evolve. We introduce collaborative effort scaling, a framework that captures how an agent’s utility grows with increasing user involvement and reveals critical gaps in current agents’ ability to sustain engagement and scaffold user understanding.
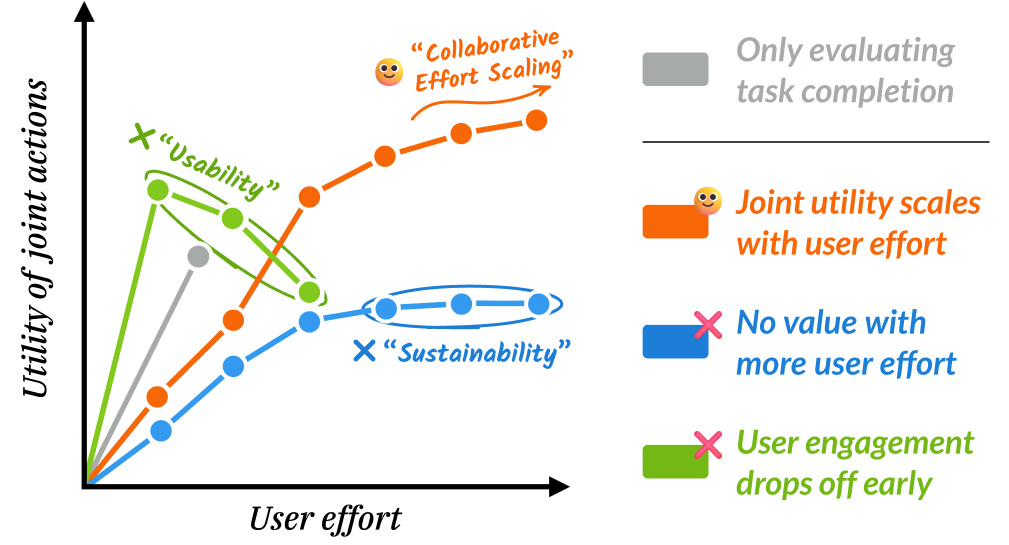
Compared to traditional task-completion-based agent evaluation (grey), our collaborative effort scaling framework can detect different types of agent behavior considering the trade-off between user effort and joint utility (green, orange, and blue). An ideal agent provides value as users spend more effort—“interaction sustainability”—and “maximizes usability” to allow for sufficient user interaction and avoid early termination.
Overview
Large Language Model (LLM) agents capable of handling complex tasks are becoming increasingly popular: Given a task description, we want agents that can automatically engage in long-form reasoning, interact with environments, and use tools effectively, with minimal human guidance. As a result, agent development has largely focused on producing high-quality, final outputs in one shot, which we refer to as task completion agents.
Consider a data scientist working with an agent to analyze a coffee survey dataset. The agent can deliver a comprehensive report with hundreds of lines of code, visualizations, and conclusions after the user typing a simple prompt. While technically complete, the report is hard to digest, contains unnoticed incorrect assumptions, and leaves the data scientist struggling to ask meaningful follow-up questions. The agent fulfilled the request but failed to support the real goal: helping the user build a deep understanding of their data through incremental, guided exploration.
However, this dominant paradigm obscures a fundamental limitation: real-world tasks are rarely completed in one shot. Many are inherently iterative and collaborative, requiring the agent not just to solve a problem but to work with a human in navigating it (Little et al., 2010; Russell et al., 1993; Wu et al., 2023). For example, in complex knowledge work, such as data analysis, users may not know exactly what insights they want to explore until they have seen partial results and uncovered previously unknown constraints. In such cases where human goals are inevitably underspecified, agents that assume static targets risk producing technically “complete” but practically useless outputs. More generally, such agents frequently underperform in multi-turn settings as they prematurely generate overly polished answers that are hard to digest, fail to incorporate user feedback, and offer little transparency into their reasoning.
We argue that desirable collaborator agents should be evaluated on their ability to appropriately leverage human effort to improve task completion. Agent utility is a product of the collaboration process, not just its endpoint. The evaluations should incorporate two human-centered dimensions of collaborative agents:
- User Effort — how much cognitive and investigative work users invest in the collaboration process, which may involve actively building an understanding of the task or the agent’s reasoning process, or simply answering the agent’s clarification prompts;
- Utility of Joint Actions — how much the joint human and agent team can accomplish together, reminiscent of joint human-AI team performance studied in prior literature (Bansal et al., 2021).
Taking inspiration from the scaling laws in machine learning (Hoffmann et al., 2022; Kaplan et al., 2020), we capture these two dimensions through the concept of collaborative effort scaling: a framework analyzing how well an agent’s utility impacts and scales with increasing user involvement. It studies two desired properties of collaborative agents: interaction sustainability, where agents should generate greater value with more user effort, and maximum usability, where agents should encourage and sustain engagement across longer interactions when needed, especially in tasks where deeper understanding or high-stakes decisions are involved.
We apply this framework to study existing human agent collaboration setups in a simulated environment by (Shao et al., 2024). We find that for complex, real-world knowledge tasks like travel planning (Xie et al., 2024), additional user effort frequently leads to minimal or no improvement compared to a fully autonomous baseline. Analysis of the collaboration reveals a key issue is agent reliance on a seemingly recursive problem-solving approach: they focus on completing immediate, individual tasks or user asks, but fail to develop and follow a coherent global plan for meaningful, long-term interactions necessary for the task.
Framework
Formalization
We study the whole collaboration process through the joint action trace between the human and agent: $\mathbf{a} = [ a_1^{(l_1)}, a_2^{(l_2)}, \dots, a_T^{(l_T)} ]$, where $T$ is the total number of steps, and $l_t \in {\text{human}, \text{agent}}$ indicates which party is taking action at step $t$. Each action is based on a corresponding context window $\mathbf{c} = [ c_1^{(l_1)}, c_2^{(l_2)}, \dots, c_T^{(l_T)} ]$.
The handoff between human and agent breaks down the process into rounds: \(\mathbf{a}_k = \mathbf{a}_{[i_k:j_k]}\) where $i_k$ and $j_k$ are the start and end step of the action. One round may start with a user action and be followed by multiple agent actions, possibly including silent internal steps such as planning or retrieval, or an actual output update (e.g., generating a revised itinerary). Likewise, a user might act several times before handing control back.
We use the handoff between human and agent to split the collaboration process into rounds: each round may contain zero or more user actions.
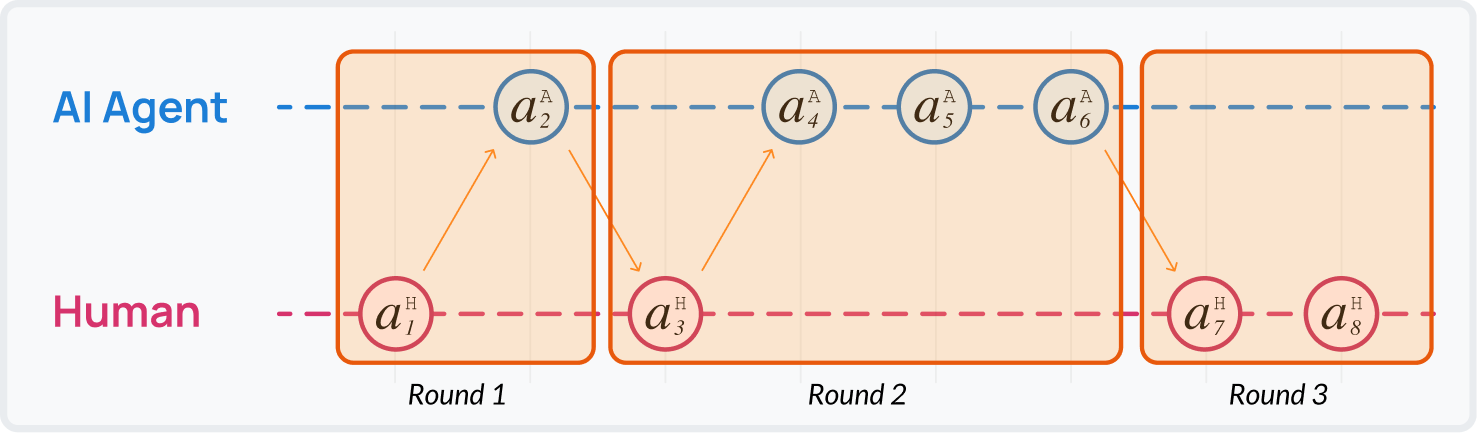
The entire procedure can be further divided into two stages. The first is the initial request stage, during which the agent produces a preliminary draft of the output. This stage concludes when $a_i^{\text{agent}}$ generates the first substantial version at step $i$. The process then transitions into a refinement stage, where the agents iteratively adjust and improve the output in response to human feedback.
In this framing, both human effort \(\mathbf{E}\) and agent utility \(\mathbf{U}\) could be approximated in multiple ways. For instance, a basic measure of human effort could be the number of human-led rounds, |\(\mathbf{a}^{\text{human}}\)|. This can be enriched by summing the contextual tokens the human processes $\sum \mathbf{c^A}$, which captures not just frequency but also cognitive load—”Is this easy to read and respond to?” Additionally, effort may reflect action type: if users default to vague queries in response to specific model errors, this might signal that parsing or evaluating the context is prohibitively hard, so users defer the burden by moving the conversation forward.
Similarly, agent utility could be tied to per-round performance score $P_{k}$ when utility is focused on the agent outcome. In more granular setups, utility could also consider additional aspects that move the collaborative team towards the final outcome, even if the output is not updated. For example, a positive move could also be the agent correctly resolves user clarifications or provides more information, even if the final answer is unchanged.
Metric Design
With the human effort and agent utility forming the trajectory, we can further capture the key metrics related to sustainability and usability:
-
Overall utility. Given unlimited human effort, what’s the maximum value an agent can provide? We define a utility function across the entire interaction period as:
\[\mathbf{U} = \frac{1}{N} \sum_{i=1}^N \max {U_k^{(i)}},\]where $N$ is the total number of instances in the evaluation (e.g., number of travel planning requests), and $\max {U_k^{(i)}}$ represents the maximum utility value for one given instance $i$.
-
Refinement gain. Building on the intuition that most of the interaction value comes from the refinement stage (i.e., most people will interact with the model at least until they get the first draft), we define a metric more focused on the additional gain from the refinement:
\[\mathbf{G} = \frac{1}{N}\sum_{i=1}^N{\max {U_k^{(i)}}-U_{k'_{i}}^{(i)}},\]where $k’_{i}$ is the first round where the agent updates the output for the $i$-th task.
-
Usability drop. We formalize the observation that when an agent fails to make consistent progress in the collaboration, the user may stop interacting due to frustration and dissatisfaction, and measure the utility—performance reached according to certain no-progress tolerance, defined by a tolerance threshold $\tau$. For the $i$-th task, the user will stop the collaboration at step $k_{i,\tau}$ if the agent fails to make satisfactory progress for at most $\tau$ rounds. The performance drop under $\tau$ is defined as:
\[\mathbf{D}@\tau = \frac{1}{N}\sum_{i=1}^N{U_{k_{i,\tau}}^{(i)} - U_{K_i}^{(i)}}.\]Notice that here we contrast $U_{k_{i,\tau}}^{(i)}$ with $U_{K_i}^{(i)}$, the performance of the agent at the end of the collaboration process, as a counterfactual measurement of the performance the agent can achieve if the user continues to interact with the agent.
Simulated Experiments
We showcase the benefit of our framework through a simulation study, following recent work that approximates human behaviors (Dubois et al., 2023; Park et al., 2023; Zhou et al., 2023). Specifically, we simulate users with LLMs interacting with agents and adopt the simplest proxies for measurement: we use the performance score $P_k$ of round $k$ as a stand-in for utility, and the number of rounds as a proxy for human effort. This setup simplifies our broader framework but serves as a first step to study collaborative effort scaling in a controlled environment. As we show below, even this minimal instantiation is sufficient to highlight differences between agents powered by different LLMs and prompts.
Setup. We use the Collaborative-Gym (Shao et al., 2024) environment that allows for asynchronous human and agent actions, which mimics the realistic interaction process. In this study, we focus on the travel planning task (Xie et al., 2024):
Given an initially high-level description of the user’s travel goal, e.g., “Help me plan a 5-day trip from Omaha to Michigan starting on 2022-03-19,” the agent will work with the simulated user to draft a travel plan that includes the itinerary, accommodation, and transportation. Throughout an iterative collaboration process, the agent can elicit the user’s latent preferences and constraints, and both parties can use tools to retrieve travel information and edit the final travel plan together.
Metric. The agent performance is measured by the quality of the generated travel plan. We adopt the script by (Xie et al., 2024) that uses an LM to determine whether the derived plan satisfies common sense (commonsense pass rate) or user constraints (constraint pass rate), and report the arithmetic average as the performance. The same evaluation is used for both the output or any intermediate rounds with a travel plan updated to obtain $P_k$.
Implementation. The Co-Gym environment comes with an automated agent implementation based on the ReAct framework (Yao et al., 2023), as well as two collaborative agent implementations: one- and two-stage planning agents. In the process, the collaborative agent can opt to send messages to the simulated user. The difference between the one- and two-stage planning agent is that the latter incorporates an additional planning step to determine whether to collaborate given the current state of the task and the user. We test both commercial and open-source LMs, i.e., GPT-4o (gpt-4o-2024-08-06), Claude 3.5 Sonnet (claude-3-5-sonnet-20241022), Claude 4.0 Sonnet (claude-4-0-sonnet-20250514), and Llama-3.1-70B: the agent prompts remain the same when we test with different LMs.
Simulated user. The simulated user is also a prompted agent based on gpt-4o with additional access to the user’s preferences and goals of the task. Besides taking actions and providing feedback, it also gives a satisfaction rating for the agent’s action during one round: for a round of actions $\mathbf{a}_k$, it produces a 5-point Likert score that assesses whether the agent actions are making progress towards the end goal. The interaction stops when either party finds the task is done or the total interaction actions exceed a maximum number of 30 rounds.
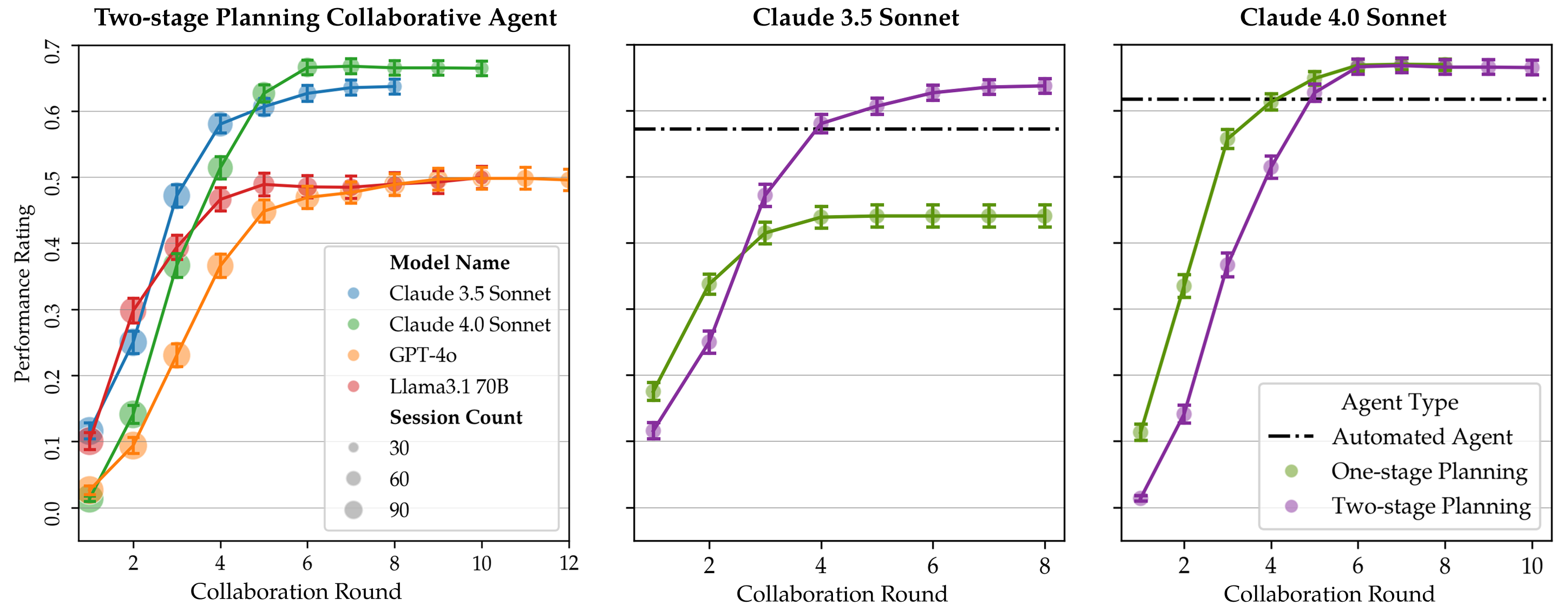
Collaborative scaling curves comparing different models and agent implementations. The left-most plot compares different LLMs: claude-3.5-sonnet and claude-4.0-sonnet show similar trends of effectively leveraging user effort, with performance improving quickly and stabilizing at higher values compared to other models. The right two plots compare one-stage versus two-stage planning agents for claude-3.5-sonnet (middle) and claude-4.0-sonnet (right). Notably, claude-4.0-sonnet’s one-stage agent can more efficiently work with the simulated user compared to claude-3.5-sonnet’s one-stage agent.
Results
The performance change during the collaboration process for different models and agents shows that agents based on different LMs show a generally similar collaborative effort scaling trend: there is a process of improvement at the beginning of collaboration, and the performance plateaus after around five rounds of interaction for all the agents.
Surprisingly, for gpt-4o and llama-3.1-70b, we find that collaborating with the user does not lead to better performance compared to the fully autonomous baseline. After inspecting the event log, we find that the collaborative version has a stronger tendency to get into loops of actions, resulting in less effective collaboration and lower performance. Neither collaborative agent implementation leads to very different performance.
When comparing different collaboration strategies, we find that the two-stage collaboration strategy leads to a significant performance boost for claude-3.5-sonnet. Not only does it achieve better performance than the one-stage planning version, but it also achieves much better performance against the automated baseline. The metrics offer additional insights: despite claude-3.5-sonnet having the best refinement gain in the one-stage planning case, the lower utility of the first update hinders the subsequent improvement. It shows that, while the two-stage collaboration planning agent may take extra effort at the beginning, it can lead to a better first product, which is crucial for good final performance.
In contrast, claude-4.0-sonnet shows a different pattern where the one-stage and two-stage strategies achieve nearly identical final utilities (0.680 vs 0.681). The one-stage planning agent reaches high performance more quickly, while the two-stage version initially lags before converging to similar levels. The metrics reveal a trade-off: while both strategies have comparable refinement gains (5.7% vs 5.2%), the two-stage approach incurs a substantially larger usability drop (-34.9% vs -20.6%), indicating a less efficient collaboration process. This suggests that less capable models (e.g., claude-3.5-sonnet) may require more structured interaction scaffolds to achieve comparable performance to stronger models (e.g., claude-4.0-sonnet), highlighting the importance of adaptive collaboration frameworks that tailor interaction complexity to the underlying model’s capabilities.
Table 1 presents the detailed metrics for both one-stage and two-stage collaboration planning agents across different language models for the travel planning task.
| Model Name | Automated Baseline |
Utility | Refinement Gain | Usability Drop | ||||
|---|---|---|---|---|---|---|---|---|
| First update | Final step | Overall | Abs. | Rel. | Abs. | Rel. | ||
| One-stage Collaboration Planning | ||||||||
claude-4.0-sonnet |
0.617 | 0.643 | 0.672 | 0.680 | 0.037 | 5.7% | -0.138 | -20.6% |
|
0.572 | 0.396 | 0.441 | 0.450 | 0.054 | 13.6% | -0.131 | -29.7% |
gpt-4o |
0.518 | 0.483 | 0.479 | 0.507 | 0.024 | 4.9% | -0.099 | -20.8% |
llama-3.1-70b |
0.482 | 0.498 | 0.496 | 0.534 | 0.036 | 7.1% | -0.090 | -18.0% |
| Two-stage Collaboration Planning | ||||||||
claude-4.0-sonnet |
0.617 | 0.647 | 0.665 | 0.681 | 0.034 | 5.2% | -0.232 | -34.9% |
claude-3.5-sonnet |
0.572 | 0.647 | 0.637 | 0.687 | 0.040 | 6.2% | -0.215 | -33.7% |
gpt-4o |
0.518 | 0.497 | 0.492 | 0.544 | 0.047 | 9.5% | -0.194 | -39.3% |
llama-3.1-70b |
0.482 | 0.514 | 0.498 | 0.539 | 0.025 | 4.9% | -0.154 | -30.9% |
Analyzing the Agent-User Effort Trade-off
To better understand the dynamics underlying the collaborative effort scaling, we analyze the distribution of effort between the agent and user throughout the interaction process. We use total tokens generated by the agent and simulated user as a measure of effort.
Analysis of agent-user effort trade-offs across different models. Left: Scatter plots where each dot represents a travel planning task. The x-axis shows total tokens generated by the simulated user and the y-axis shows total tokens generated by the execution agent. Dashed lines indicate relative effort ratios (agent tokens / user tokens); moving toward the top-left indicates less relative user effort. Right: Performance distributions bucketed by agent-to-user effort ratio reveal how joint performance varies with the balance of contributions. Each row represents a different model.
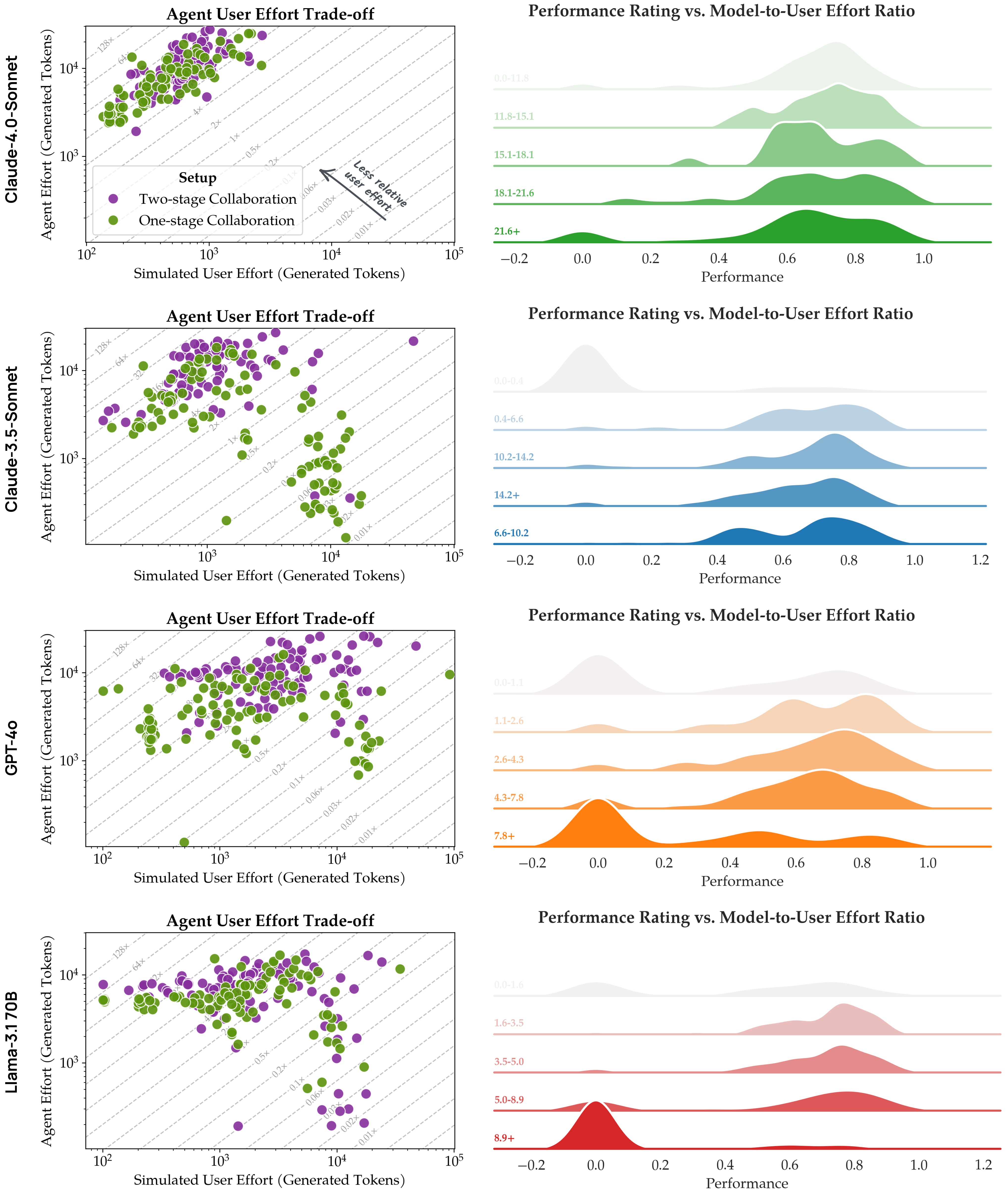
User effort varies significantly across models despite similar agent effort. Across most models, agents generate a relatively consistent amount of tokens (between \(10^3\) and \(10^4\)). However, the primary differentiator lies in how much effort is required from the simulated user: models other than claude-4.0-sonnet—particularly gpt-4o and llama-3.1-70b—often require substantially more user tokens without yielding proportional improvements in final performance. This suggests that less capable models may fail to efficiently extract and utilize user input, leading to prolonged interactions with diminishing returns. However, claude-3.5-sonnet is the exception in the set of models we considered; it exhibits a clear separation in agent effort between the two strategies, suggesting that the model’s collaborative behavior is more heavily influenced by the interaction scaffold.
A sweet spot exists in the effort distribution. When we consider performance ratings, we find a nuanced relationship between effort balance and task success. For each model, there appears to be an optimal range of agent-to-user effort ratios where performance peaks. When either the user contributes disproportionately more effort (low agent-to-user ratio) or the agent dominates the interaction (high agent-to-user ratio), joint performance tends to degrade. Notably, this sweet spot is model-dependent: claude-4.0-sonnet achieves strong performance across a broader range of effort ratios, while gpt-4o and llama-3.1-70b show more pronounced performance degradation outside their optimal ranges. This finding underscores the importance of calibrating collaboration patterns to match the underlying model’s capabilities.
Discussion
Our results suggest that current agents are not merely underperforming—they are fundamentally misaligned with the dynamics of real collaboration, suggesting opportunities to rethink agent design.
Utility and effort require thoughtful, human-centered proxies. Our case studies reveal that common proxies for “success,” such as task completion or engagement frequency, overlook the nuanced ways utility and effort manifest in practice. Effort encompasses not only interaction frequency but also cognitive load, sensemaking, and confusion; utility extends beyond output quality to include how agents scaffold understanding, support exploration, and clarify ambiguity. Richer behavioral traces—such as edit histories, timing patterns, and clarifying requests—could help approximate these dimensions, as in recent adaptive programming systems (Chen et al., 2025).
Mixed-initiative interaction should follow effort–utility dynamics. Agents must not only respond effectively but also decide when to act, defer, or prompt—decisions that depend on the evolving balance between user effort and perceived utility. Structuring mixed-initiative interaction (Horvitz, 1999) around this trajectory allows agents to intervene when progress stalls and step back when users regain momentum. Achieving this requires modeling collaboration as a dynamic control process.
Model capability shapes optimal collaboration strategies. Our results reveal that not only should collaboration strategies be tailored to the underlying model’s capabilities (e.g., claude-3.5-sonnet versus claude-4.0-sonnet), but also performance difference should not be the only metric considered (e.g., the difference in usability drop between strategies for claude-4.0-sonnet). For agent builders, this highlights the importance of profiling the collaborative capabilities of underlying models before committing to interaction patterns. Rather than applying uniform collaboration frameworks, systems should incorporate manual scaffolding—such as structured planning stages, explicit constraint verification, or guided decomposition—selectively, based on where models demonstrate weaknesses in collaborative settings.
Collaboration design remains essential as models improve. Our results, along with other recent findings, demonstrate that today’s models benefit substantially from multi-agent interactions—the collaborative approach consistently outperforms fully autonomous baselines. Our results show that how a model collaborates significantly impacts overall performance, and that designing for collaboration may be beneficial not only for human-AI collaboration but also potentially for agent-agent collaboration. While model capabilities will continue to improve and narrow performance gaps between collaboration and autonomous baselines, the fundamental need for human-AI collaboration will persist: real-world tasks are inherently underspecified, and human requirements are difficult to fully articulate upfront.
Conclusion
In this work, we introduce collaborative effort scaling as a framework for evaluating human-agent collaboration beyond traditional task-completion metrics. Through formalizing the relationship between user effort and joint utility, we demonstrate how current agents often fail to leverage human input effectively, particularly in complex, underspecified domains. Our simulated experiments reveal that even state-of-the-art models struggle with sustained collaboration, frequently plateauing after minimal interaction or falling into unproductive loops. The framework’s key insights—that agents must demonstrate interaction sustainability and maintain maximum usability, and that collaboration requires dynamic adaptation to evolving user understanding—point toward fundamental shifts needed in agent design. As AI systems increasingly enter real-world collaborative contexts, measuring and optimizing these interaction dynamics will be crucial for building agents that truly enhance rather than replace human capabilities.
References
- Little, G., Chilton, L. B., Goldman, M., & Miller, R. C. (2010). Exploring iterative and parallel human computation processes. Proceedings of the ACM SIGKDD Workshop on Human Computation, 68–76.
- Russell, D., Stefik, M., Pirolli, P., & Card, S. (1993). The cost structure of sensemaking. INTERCHI.
- Wu, T., Zhu, H., Albayrak, M., Axon, A., Bertsch, A., Deng, W., Ding, Z., Guo, B., Gururaja, S., Kuo, T.-S., & others. (2023). Llms as workers in human-computational algorithms? replicating crowdsourcing pipelines with llms. ArXiv Preprint ArXiv:2307.10168.
- Bansal, G., Wu, T., Zhou, J., Fok, R., Nushi, B., Kamar, E., Ribeiro, M. T., & Weld, D. S. (2021). Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance.
- Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. de L., Hendricks, L. A., Welbl, J., Clark, A., & others. (2022). Training compute-optimal large language models. ArXiv Preprint ArXiv:2203.15556.
- Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling laws for neural language models. ArXiv Preprint ArXiv:2001.08361.
- Shao, Y., Samuel, V., Jiang, Y., Yang, J., & Yang, D. (2024). Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration. https://arxiv.org/abs/2412.15701
- Xie, J., Zhang, K., Chen, J., Zhu, T., Lou, R., Tian, Y., Xiao, Y., & Su, Y. (2024). TravelPlanner: A Benchmark for Real-World Planning with Language Agents. ArXiv.org.
- Kaelbling, L., Littman, M., & Cassandra, A. (1998). Planning and Acting in Partially Observable Stochastic Domains. Artificial Intelligence, 101, 99–134.
- Dubois, Y., Li, C. X., Taori, R., Zhang, T., Gulrajani, I., Ba, J., Guestrin, C., Liang, P. S., & Hashimoto, T. B. (2023). Alpacafarm: A simulation framework for methods that learn from human feedback. Advances in Neural Information Processing Systems, 36, 30039–30069.
- Park, J. S., O’Brien, J., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. Proceedings of the 36th Annual Acm Symposium on User Interface Software and Technology, 1–22.
- Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., & others. (2023). Sotopia: Interactive evaluation for social intelligence in language agents. ArXiv Preprint ArXiv:2310.11667.
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). React: Synergizing reasoning and acting in language models, 2023. URL Https://Arxiv. Org/Abs/2210.03629.
- Chen, V., Zhu, A., Zhao, S., Mozannar, H., Sontag, D., & Talwalkar, A. (2025). Need Help? Designing Proactive AI Assistants for Programming. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 1–18.
- Horvitz, E. (1999). Principles of mixed-initiative user interfaces. International Conference on Human Factors in Computing Systems, 159–166.
Citation
@article{shen2025designing,
title={Completion $\neq$ Collaboration: Scaling Collaborative Effort with Agents},
author={Shen, Shannon Zejiang and Chen, Valerie and Gu, Ken and Ross, Alexis and Ma, Zixian and Gu, Alex and Si, Chenglei and Ross, Jillian and Shen, Jocelyn J and Chi, Wayne and Peng, Andi and Talwalkar, Ameet and Wu, Tongshuang and Sontag, David},
journal={arXiv preprint arXiv:2510.25744},
year={2025}
}