Recently, we’ve seen clear collaboration gaps in today’s coding agents, which are designed for short-form, single-user chats. As human-agent collaborations grow to last days or weeks, complex collaboration patterns emerge — from managing multiple long-running agents to coordinating across human teams and agents. We propose Self-evolving Repository (Sepo), a framework for long-horizon, multi-user agent collaboration. It implements the harness to run multiple coding agents (Codex/Claude Code) natively on GitHub: it turns any GitHub repository into a living artifact with native support for long-horizon collaboration between human teams and agents. On top of this, Sepo incorporates a continual learning framework that distills team preferences from past interactions into rubrics (stored on the agent/rubrics branch), and uses them to steer future coding sessions via rubric reviews and refinement. We’ve found Sepo practically useful for managing repo-level development tasks and it can enable a range of novel human-agent coding interactions. Try it today by starting a new Sepo, or install it into an existing repository with one command.
Collaboration gaps in long-horizon human-agent work
As coding agents become more capable, people are using them for increasingly long-horizon tasks: deep research, library migrations, even full-language rewrites. Bun’s recent million-line port from Zig to Rust leaned heavily on Claude Code, and Vjeux ported 100k lines of TypeScript to Rust by running Claude Code essentially 24/7 for a month.
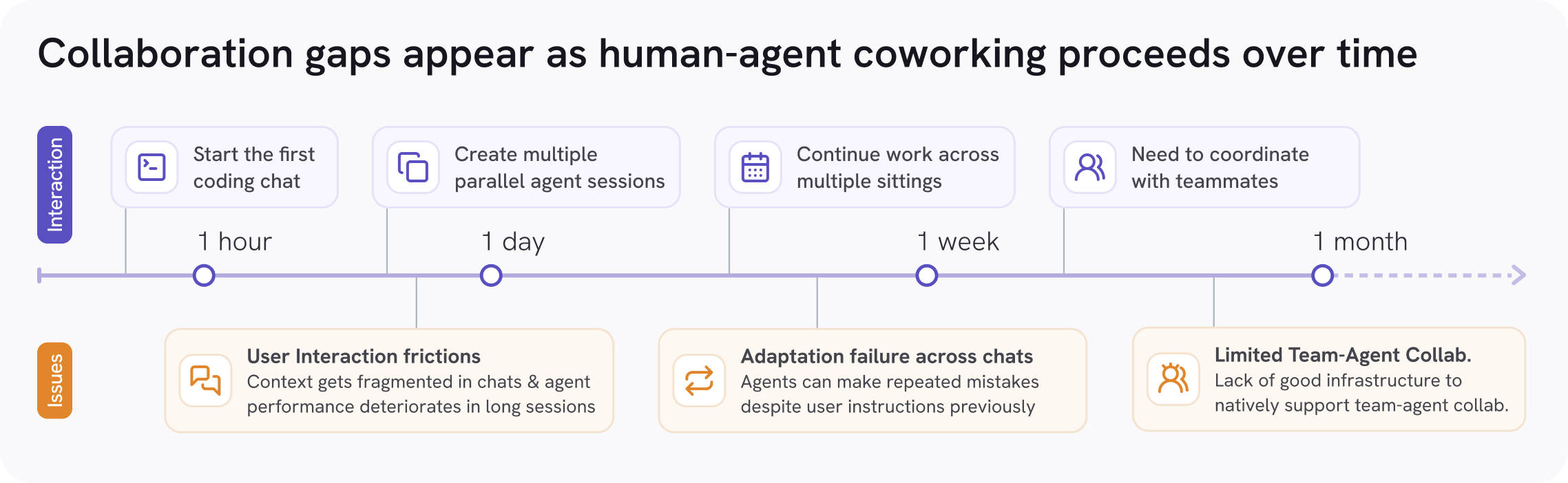
Figure 1. Collaboration gaps emerge as human–agent work scales from hours to weeks.
But as we work with agents from a single chat to hours-, days-, and weeks-long collaborations, distinct collaboration gaps appear in our experience:
Collaboration Gap
Within a sitting (hours)
- User interaction frictions arise as soon as you spin up multiple parallel agent chats — context fragments across terminal tabs and worktrees, and just managing the local artifacts (checkouts, caches, which model is in which window) adds mental burden on top of the coding itself. - Long context failure can also arise in a long-running agent chat — the agent drifts past its context window, making hidden assumptions and reaching for hacky workarounds rather than asking (Laban et al., 2025).
Across sittings (days)
- Adaptation failure: today’s coding agents often repeat the same errors across chats — force-pushing when they shouldn’t, failing to update documentation, or diving into hacky implementations the user has already rejected. Static instructions in AGENT.md only partially help, since they live in the prompt and aren’t checked at the end.
Across people (weeks)
- Limited team–agent collaboration: half-finished agent work doesn’t travel. There’s no native way for a teammate to pick up a chat, share context, or take over a draft PR without reconstructing the whole conversation from scratch.
Coordinating team–agent collaboration on GitHub
As a first step, rather than build a new app or CLI, we go back to GitHub — the place developers and researchers already collaborate every day. Sepo turns any GitHub repository into a shared workspace where humans and agents work together: mention @sepo-agent in any issue, PR, or discussion, and Sepo routes the request to one of several modes — answer questions about the code, implement new features, review code, fix bugs, orchestrate multi-step workflows, and more.
Once collaboration moves into GitHub, the rest of GitHub’s primitives become available natively. Each agent conversation (in issues, PRs, or discussions) gets a permanent link and cross-references other issues; open/closed status acts as a built-in tracker for long-running work. Repo-specific memory is stored on a dedicated agent/memory branch — framework-agnostic, shareable, versioned alongside the code, and kept out of the main commit history. Multi-step agent work is orchestrated through GitHub Actions. And because everything lives inside the repo, anyone with access can join an agent’s thread, take over a draft PR, or pick up where a teammate left off — no separate “agent collaboration model” to learn.
Two case studies illustrate what changes when team–agent collaboration lives on GitHub: first a multi-user hand-off, then a fully autonomous long-horizon sequence.
Case study: multi-user hand-off in augmented-mind#31.
One contributor opened issue #31 describing a website update in natural language — episode title, description, links, timestamps. Sepo used the issue thread to refine the plan, identified a missing asset (a cover image), and produced PR #32. Later, a different contributor supplied the missing image in the same thread, and Sepo turned that follow-up into PR #33. At no point did the two contributors share prompts, sync worktrees, or coordinate which machine was running the agent — the GitHub thread carried all of that.
Case study: long-horizon orchestration of Issue #170.
Issue #170 was a substantial feature — an earlier attempt in PR #166 had grown too large to review, so we restated the work as four independent slices. A single /orchestrate call then drove the rest: Sepo created a child issue for each slice, implemented each in its own PR, ran an implement → review → fix loop until every PR’s verdict was SHIP, and reported back to the parent issue. All four PRs — #172, #180, #184, #186 — completed autonomously over several hours. We reviewed the code only once everything was ready, focusing on high-level design instead of low-level iteration cycles.
In both cases, there is no prompt sharing between users and no hand-off ritual — the issue thread is the prompt, and the hand-off happens the way it already happens for code review. The agent doesn’t need to be “your” agent on “your” machine; it’s a teammate the repo can reach.
Evolve the repo with learned team rubrics
The GitHub-native harness closes the within-sitting and across-people gaps from Figure 1, but on its own it doesn’t address the across-sittings gap — agents still repeat in one chat mistakes the team corrected in a previous one. The conventional response is to write the rules down in a CLAUDE.md or AGENT.md. As they’re advisory prompts, they might get lost in long conversations, and there’s no check at the end that any specific rule was actually respected.
Sepo’s continual learning loop addresses both problems through rubric learning and review:
Rubric learning. Sepo monitors human–agent interactions in code reviews and discussions, identifies recurring preferences the team has expressed, and distills them into structured rubrics. Each rubric is stored on a dedicated agent/rubrics branch — like memory, framework-agnostic and versioned alongside the code.
Rubric review. When the agent reviews a new PR, it doesn’t just free-form-critique; it explicitly scores the PR against each applicable rubric. If an implementation fails a rubric, Sepo will iterate on the fix automatically before handing off to a human reviewer. Unlike instructions in AGENT.md that the agent might recall, rubrics provide a stronger guarantee: every implementation is explicitly checked against them at review time.
What’s in a rubric? Each rubric is a small YAML file with a named principle, a short rationale, and concrete examples drawn from the conversation that produced it — e.g., prefer-agent-derived-decisions.yaml (from the PR #199 discussion below) says: if the agent can infer a decision from context, don’t expose it as a configuration option. The broader idea of using evolving rubrics is also something we explore in our recent paper, DR Tulu(Shao et al., 2025).
Case study: Sepo learns a team rubric from feedback in PR #199 and applies it to improve future PRs.
In PR #199, the agent initially proposed adding a new environment variable (AGENT_INLINE_COMMENT_CLEANUP_MODE) to control how stale inline review comments are handled. A maintainer pushed back: why expose this as a repo setting when the agent can decide based on context? That conversation produced rubrics/workflow/prefer-agent-derived-decisions.yaml. Since then, the rubric has been applied in reviews across multiple PRs (#232, #235, #260, #262), and even caught a partial violation in #265, where a decision had leaked back into configuration. What started as a single review conversation became a durable check applied to every future PR — the repo learned, and the agent inherited that learning automatically.
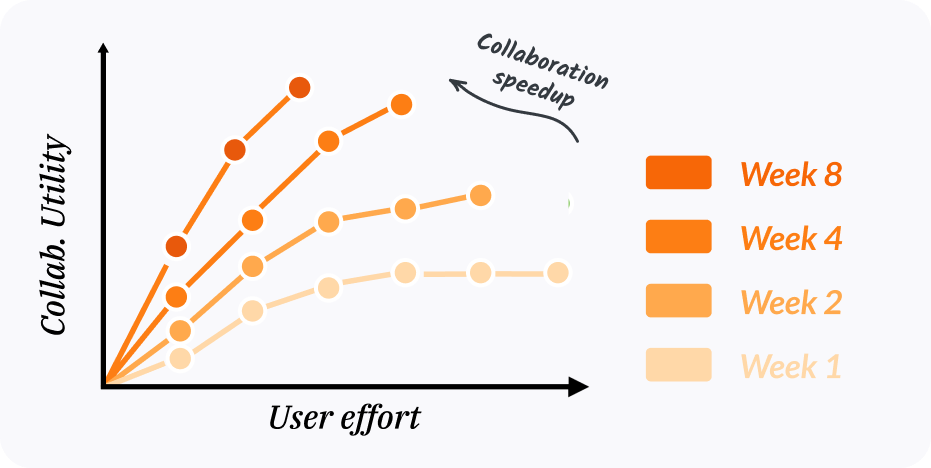
Zooming out, rubric learning and review connects to our previous work — it improves collaborative effort scaling(Shen et al., 2025) across sittings and can lead to collaboration speedups over time. Collaboration speedup extends effort scaling from within a single sitting to across many: as the team works with the agent over weeks and months, the utility per unit of user effort should increase as the agent learns from prior interactions. Today’s coding agents have largely flat speedup curves — each new sitting restarts grounding from scratch and can make repeated mistakes. Our rubric learning and review is an inference-time algorithm that can bend this curve upward: each new sitting’s implementation builds on what the team has already learned, instead of starting fresh and wasting user effort.
Figure 2. Idealized collaboration speedup — utility per unit of user effort rises as the team works with the agent over weeks.
Limitations and next steps
One clear limitation today is latency: each agent invocation goes through GitHub Actions setup, so responses aren’t instant. We’re working on bringing this down; in the short term, using a local runner significantly reduces the latency.
Sepo is still in its early stages — we’d love to share it with you and hear your feedback. While we started with coding, we’re applying the same framework to other domains — research repos, ML experiment pipelines, documentation sites — anywhere a team collaborates through a shared repository. As rubrics accumulate and memory deepens, the repository continues to evolve from a static artifact into a living system that grows with the team.
Try it today: start a new Sepo, or install it into an existing repository with one command at github.com/self-evolving/repo.
References
Laban, P., Hayashi, H., Zhou, Y., & Neville, J. (2025). LLMs Get Lost In Multi-Turn Conversation.
Shao, R., Asai, A., Shen, S., Ivison, H., Kishore, V., Zhuo, J., Zhao, X., Park, M., Finlayson, S., Sontag, D., Murray, T., Min, S., Dasigi, P., Soldaini, L., Brahman, F., Yih, W.-tau, Wu, T., Zettlemoyer, L. S., Kim, Y., … Koh, P. W. (2025, November). DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research. ArXiv.org. https://doi.org/10.48550/arXiv.2511.19399
Shen, S., Chen, V., Gu, K., Ross, A., Ma, Z., Ross, J., Gu, A., Si, C., Chi, W., Peng, A., Shen, J. J., Talwalkar, A., Wu, T., & Sontag, D. A. (2025). Completion ≠Collaboration: Scaling Collaborative Effort with Agents. ArXiv Preprint ArXiv:2510.25744. https://arxiv.org/abs/2510.25744