2025
LaText: Interleave Latent and Text Chain-of-Thought for efficient reasoning
I gave a talk on our recent work on LaText, a novel approach to interleave latent and text chain-of-thought for efficient reasoning.

Rethinking the Design and Evaluation of Human and LLM Collaboration
I shared an initial version of our collaborative effort scaling paper, and discussed the HCI aspects of our previous work on Symbolic Generation.

2024
Co-LLM: Training LLMs to Decode Collaboratively
This talk is hosted by Luke Zettlemoyer’s group. We go through the details of our ACL paper Co-LLM. You can find the slides here.

Developing User-Friendly Language Language Model Systems
This talk is hosted by Chiyuan Zhang and Yangsibo Hunag. We focused on the Co-LLM project and had a deep dive in the methodology and experiments. Slides available upon request.
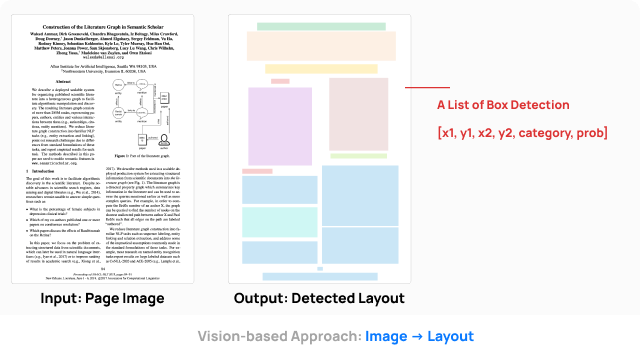
LayoutParser and Historical Document Image Processing
We reviewed the LayoutParser design and functionality, as well as approaches to tackle historical image processing and extraction in 2024. Slides available upon request.
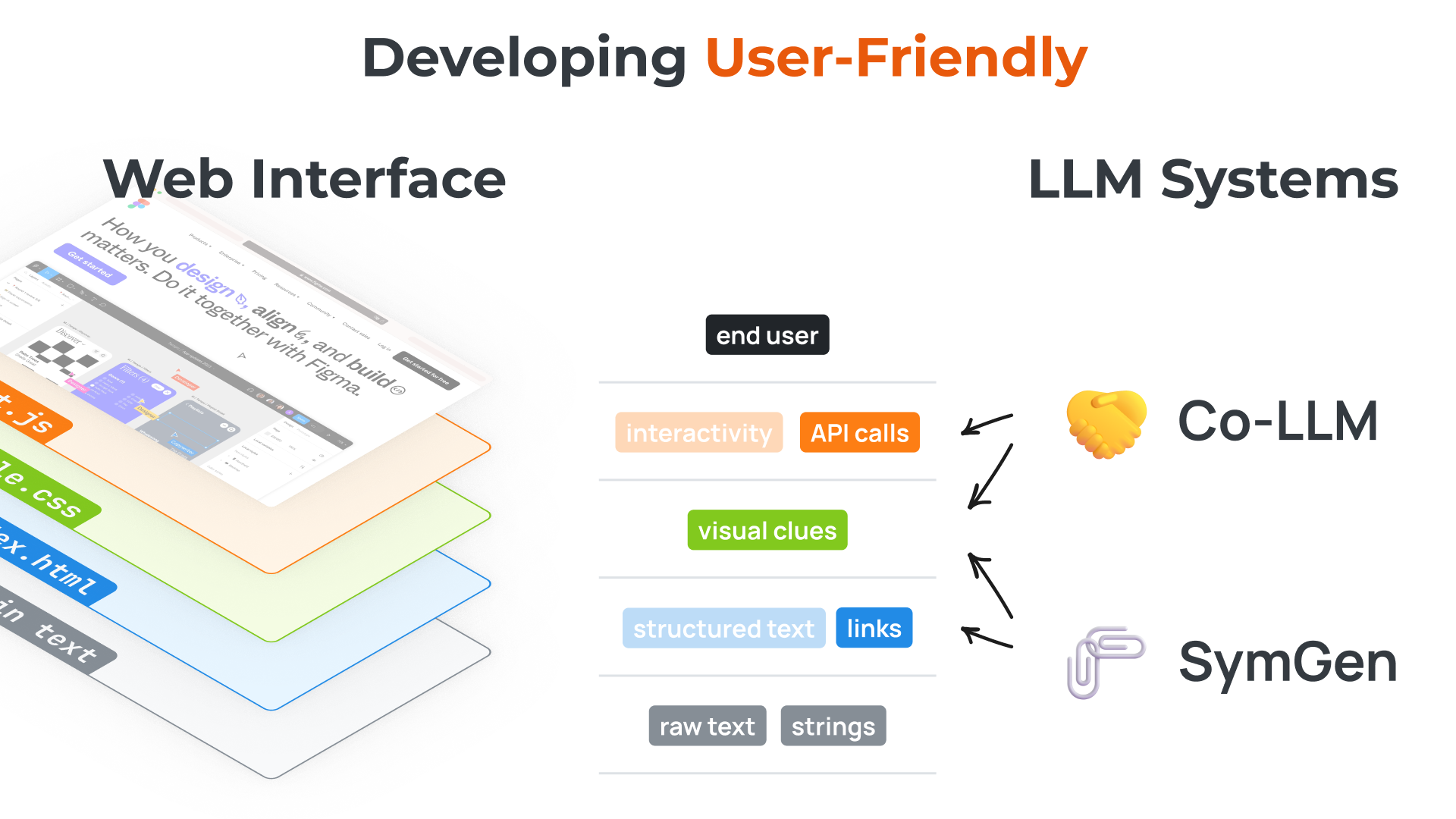
Developing User-Friendly Language Language Model Systems
We start with the analogy between web interface development and llm development: LLM can produces raw text (as if htmls for the web pages) – what is the CSS and javascript in the context of LLMs? We then talk about two recent projects, Co-LLM and SymGen, drawing connections between our methods and web technologies like CSS, API calls, etc. Slides available upon request.
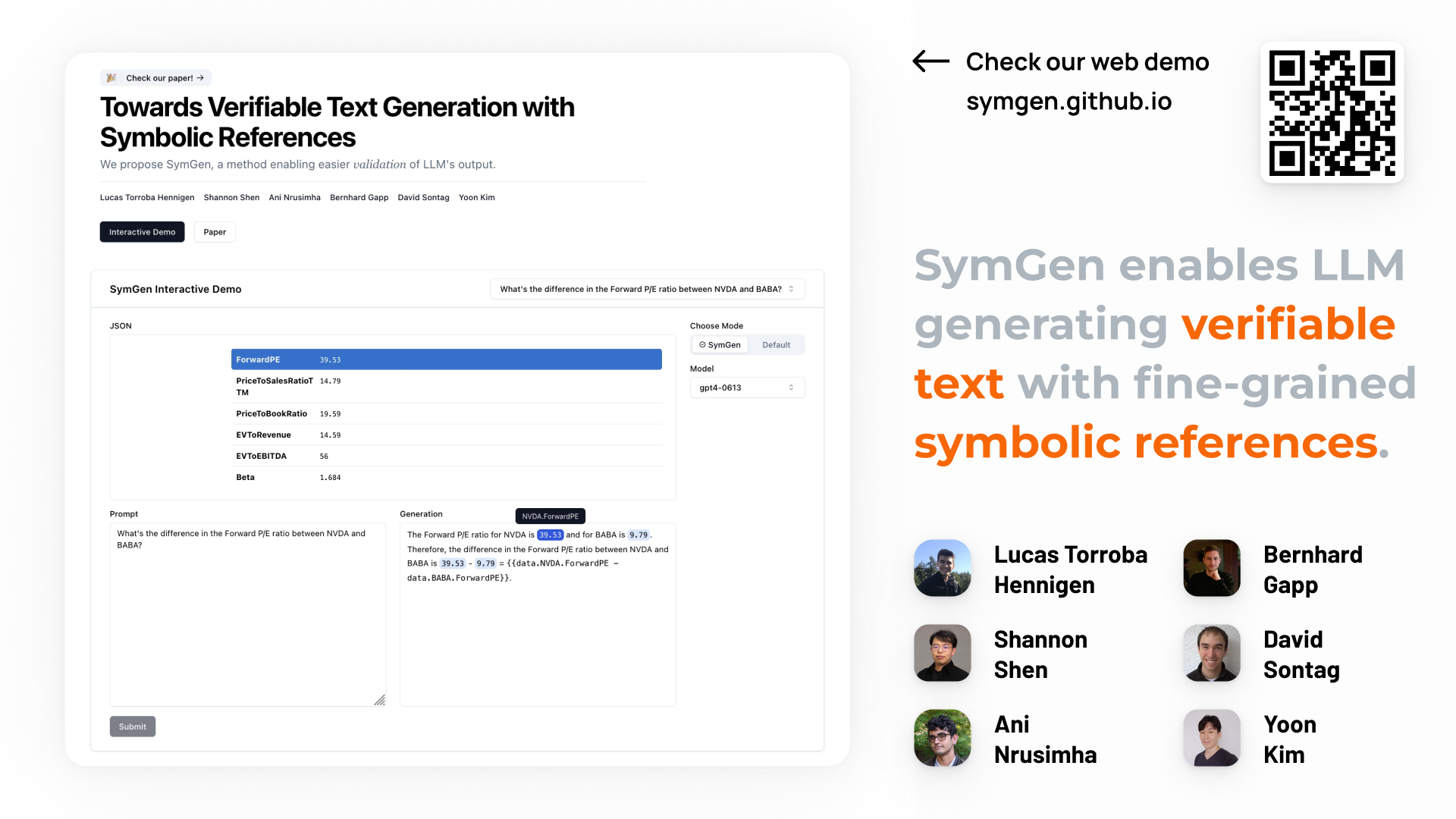
Towards Verifiable Text Generation for Developing Trustworthy LLMs
In this short talk, we cover our latest research on SymGen, a novel approach to generating verifiable text for developing trustworthy LLMs. Slides available upon request.
LayoutParser and Historical Document Image Processing
We reviewed the LayoutParser design and functionality, as well as approaches to tackle historical image processing and extraction in 2024. Slides available upon request.
Visual Design in Scholarly Communication
A series of lectures over the MIT IAP period, co-taught with Lucas Torroba Hennigen, focused on visual design in scholarly communication. Visual design is a crucial element in various forms of scientific communication, ranging from papers, slides, to even videos. While there is an increasing need for researchers to produce high-quality visuals, it remains to be a time-consuming and sometimes very challenging task. Despite the significant role they play, there is a noticeable lack of formal education dedicated to this aspect. This subject aims to cover several key topics about visual designs in scholarly communication.
2023
Redesigning Clinical Documentation
We took the inspiration from our position paper on AI supported expository writing and discuss how to apply such ideas in clinical documentation. This is a joint presentation with Monica Agrawal and Hunter Lang.

2022
Multi-LexSum: Real-world Summaries of Civil Rights Lawsuits at Multiple Granularities
A presentation of our work on the Multi-LexSum dataset, containing real-world summaries of civil rights lawsuits at multiple granularities.
Visual Content Extraction for Scientific Documents
We reviewed the general problem of visual content extraction in scientific documents, as well as the current state-of-the-art methods and challenges. Slides available upon request.